
Input from unseen subjects
Our framework works successfully even when motions from unseen subjects with different body proportions are given as input.
Transforming neutral, characterless input motions to embody the distinct style of a notable character in real time is highly compelling for character animation.
This paper introduces MOCHA, a novel online motion characterization framework that transfers both motion styles and body proportions from a target character to an input source motion. MOCHA begins by encoding the input motion into a motion feature that structures the body part topology and captures motion dependencies for effective characterization. Central to our framework is the Neural Context Matcher, which generates a motion feature for the target character with the most similar context to the input motion feature. The conditioned autoregressive model of the Neural Context Matcher can produce temporally coherent character features in each time frame. To generate the final characterized pose, our Characterizer network incorporates the characteristic aspects of the target motion feature into the input motion feature while preserving its context. This is achieved through a transformer model that introduces the adaptive instance normalization and context mapping-based cross-attention, effectively injecting the character feature into the source feature.
We validate the performance of our framework through comparisons with prior work and an ablation study. Our framework can easily accommodate various applications, including characterization with only sparse input and real-time characterization. Additionally, we contribute a high-quality motion dataset comprising six different characters performing a range of motions, which can serve as a valuable resource for future research.
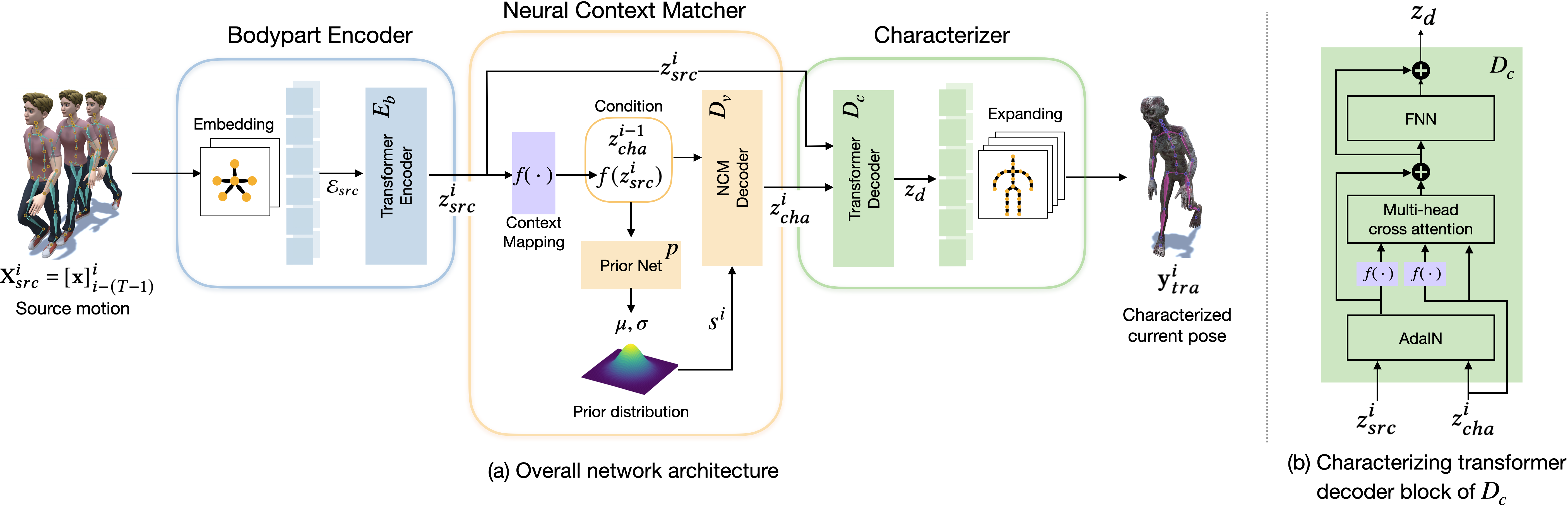
Network configuration. (a) Overall architecture for motion characterization in run-time. Our framework consists of bodypart encoder, neural context matcher, and characterizer networks. (b) Detail of the characterizer transformer decoder block (𝐷𝑐).
Our framework works successfully even when motions from unseen subjects with different body proportions are given as input.
Our framework could work with sparse inputs from the hip and end-effectors as they may contain essential information about context and style.
We demonstrate the ability of our framework to characterize streamed motion data in real-time. Video shows live characterization of a streamed motion captured with Xsens Awinda sensor. Our method can produce successfully characterized motion even with network delays and noisy input data.
@inproceedings{jang2023mocha,
title={Mocha: Real-time motion characterization via context matching},
author={Jang, Deok-Kyeong and Ye, Yuting and Won, Jungdam and Lee, Sung-Hee},
booktitle={SIGGRAPH Asia 2023 Conference Papers},
pages={1--11},
year={2023}
}